Willem Hoek
Automate your Jira reporting with Python and Excel
Nov 14, 2020

Salvador Dalí, The Persistence of Memory, 1931
Jira
Jira is a tool used for project and issue management by more than a million users from 100,000+ companies. Jira comes with great reporting functionality and you can create custom Excel reports by manually exporting Jira items. However, if you do the same task regularly e.g. a Daily Status Report – you may want to fully automate the process.
This post will show you how you can programmatically create Jira Reports in Excel using open-source software (Python) and libraries. The program will perform the following steps:
- Pull Jira issues using the Jira API
- Parse the extracted data (in JSON format) and save it to a database (SQLite)
- Produce an Excel report (XLSX format) from the database
It is not for Jira beginners and some very basic knowledge of Python is required.
Manually extract data from Jira
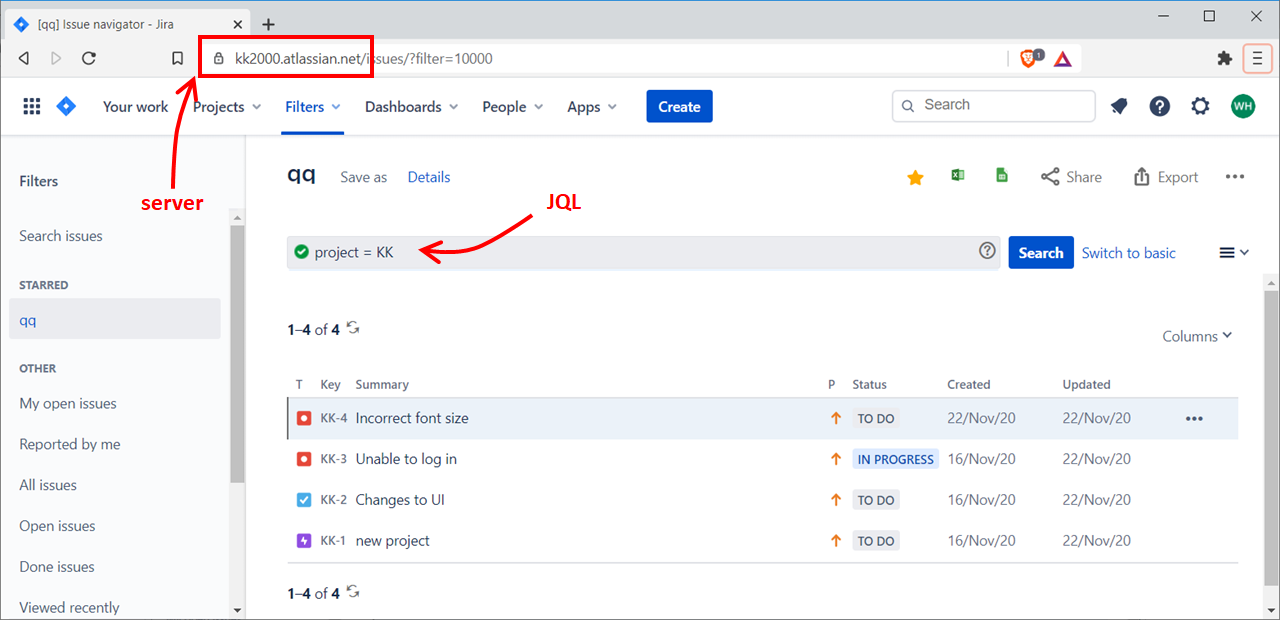
Before we automate anything, let’s first have a look at how to export Jira items manually. The automated method will be based on the same query. In Jira, go to “Filters” and select the items you want to view and export. You could press “Export” to “Export Excel CSV (all fields)”. This is the action that we want to automate in step 1.
Press “Switch to JQL” to get the filter details in Jira Query Language (JQL) format. Also note the server URL. This information will be required later on.
Automate the process using Python
Get a Jira API token
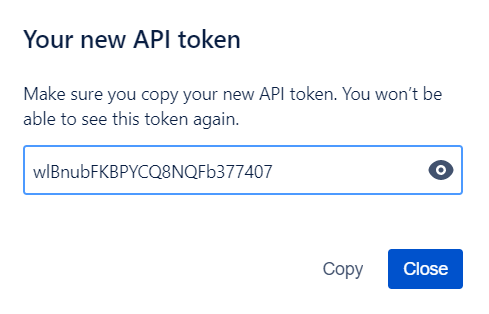
We will use a Jira API to extract the issues. You need to first create an API token for your user account. In Jira, select “Account Settings” then “Security”. Look for the option to get an API token.
Python environment
The program is written in Python (programming language). I highly suggest you use the Anaconda Python distribution [1] as it already contains most of the libraries used such as Pandas (for data manipulation and analysis) and XlsxWriter (for creating Excel files). If you don’t use Anaconda – you may need to first install those packages using pip install.
If you are using Anaconda – the only additional package to install is Python Jira [2]. This is done with the following command in the Anaconda prompt.
conda install jira
A bare bones working program is listed below to show the key concepts. The only change required is to add your own user settings and JQL to extract the issues.
from jira.client import JIRA
import pandas as pd
import sqlite3
import xlsxwriter
# Settings
email = 'name@domain.com' # Jira username
api_token = "wlBnubFKBPYCQ8NQFb377407" # Jira API token
server = 'https://kk2000.atlassian.net/' # Jira server URL
jql = "project = KK" # JQL
# Get issues from Jira in JSON format
jira = JIRA(options={'server': server}, basic_auth= (email, api_token))
jira_issues = jira.search_issues(jql,maxResults=0)
# JSON to pandas DataFrame
issues = pd.DataFrame()
for issue in jira_issues:
d = {
'id': issue.id,
'key': issue.key,
'self': issue.self,
'assignee': str(issue.fields.assignee),
'creator' : str(issue.fields.creator),
'reporter': str(issue.fields.reporter),
'created' : str(issue.fields.created),
'labels': str(issue.fields.labels),
'components': str(issue.fields.components),
'description': str(issue.fields.description),
'summary': str(issue.fields.summary),
'fixVersions': str(issue.fields.fixVersions),
'issuetype': str(issue.fields.issuetype.name),
'priority': str(issue.fields.priority.name),
'project': str(issue.fields.project),
'resolution': str(issue.fields.resolution),
'resolution_date': str(issue.fields.resolutiondate),
'status': str(issue.fields.status.name),
'updated': str(issue.fields.updated),
'versions': str(issue.fields.versions),
'subtask': str(issue.fields.issuetype.subtask),
'status_description': str(issue.fields.status.description),
'watchcount': str(issue.fields.watches.watchCount),
}
issues = issues.append(d, ignore_index=True)
# DataFrame to SQLite
con = sqlite3.connect("jira-issues.db")
issues.to_sql("issues", con, if_exists="replace")
con.close()
# Get data from SQLite
con = sqlite3.connect("jira-issues.db")
sql = "select issuetype, count(*) count from issues group by issuetype"
df = pd.read_sql_query(sql, con)
con.close()
# Create Excel file
row = 1
col = 1
workbook = xlsxwriter.Workbook('jira-excel.xlsx')
header = workbook.add_format({'bold': True, 'align': 'center', 'bg_color': '#D8E4BC'})
center = workbook.add_format({'align': 'center'})
worksheet = workbook.add_worksheet('Summary')
worksheet.write(row, col, 'Issue Type', header)
worksheet.write(row, col + 1, 'Count', header)
row += 1
for index, dat in df.iterrows():
worksheet.write(row + index, col, dat['issuetype'])
worksheet.write(row + index, col + 1, int(dat['count']), center)
workbook.close()
print('All done!')
Total execution time is less than a second. But it all depends on how many issues you are exporting.
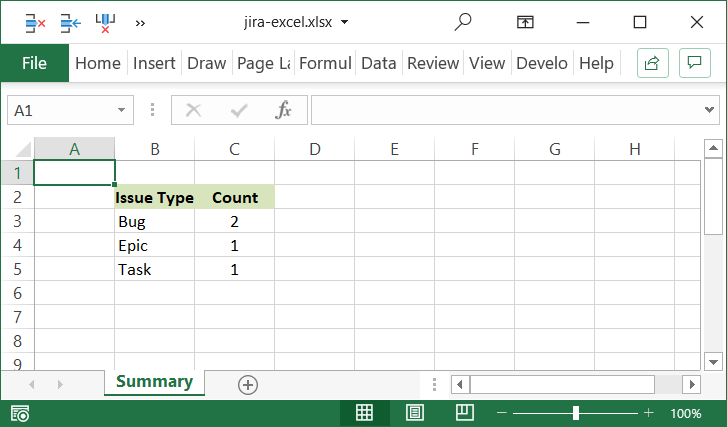
The sample program creates a very simple Excel file - see below. However, the Python XlsxWriter library [3] can create almost any Excel file that you can create manually. Including complex text/date formating, multiple sheets, filters, column/row sizing, conditional formating and charts to name a few.
Why use a database to store the data?
In the example above, the Jira data is first written to a SQL database. The Excel report pulls the data from the database. This is not technically required but provides multiple advantages such as:
- The same Jira data can be used for different reports
- By using tables in a database, it is easy to add additional (non Jira) information to your reports
- Easy way to keep history of previous Jira downloads for comparisons
- Changes to reports can be made very quickly by changing the Standard SQL rather than the code
- The SQLite database [4] is self-contained and included with Python, so no additional software is required
- You can use standard database tools to test your SQL queries, example “DB Browser for SQLite” [5]
Updates
2022-06-20: Since writing this post, I created a command line program called scrumdog to automatically download the Jira Issues to a SQLite database. Using scrumdog will eliminate a big chunck of above code. For more info, see https://scrumdog.app/.
References and further reading
[1] Python Anaconda: Your data science toolkit
https://www.anaconda.com/products/individual#Downloads, Retrieved: 2020-11-14
[2] Python Jira: Python library to work with Jira APIs
https://jira.readthedocs.io/, Retrieved: 2020-11-14
[3] XlsxWriter: Creating Excel XLSX files using Python
https://xlsxwriter.readthedocs.io/, Retrieved: 2020-11-14
[4] SQLite: Fast, self-contained, high-reliability, full-featured, SQL database
https://www.sqlite.org/, Retrieved: 2020-11-14
[5] DB Browser for SQLite
https://sqlitebrowser.org/, Retrieved: 2020-11-14
[6] Python source code on GitHub
https://github.com/whoek/jira-to-sqlite-to-excel/
Similar Posts on this website
How-to Import an Excel file into SQLite and back to Excel again
Solving the Jane Street puzzle of December 2022
Why I created Scrumdog - a program to download Jira Issues to a local database
Jane Street puzzle Feb 2021 SOLVED! OCaml to the rescue
Solving the Jane Street puzzle of Dec 2020 - Backtracking with OCaml